Log4J isn't the aggregation catastrophe because aggregation isn't a force graph, it's a sankey!
By now everyone has heard of Log4J but if you haven’t here is a tl;dr.
Log4J and CVE-2021-44228
Log4J is an open source java logging library that is widely used by many platforms (VMware, Elasticsearch, Struts, Druid,Flume, Hadoop) and many companies (Apple, Tesla, AWS, Cloudflare) that had a vulnerability discovered in November 2021 (CVE-2021-44228) that was going to bring us the end of cyber-times, except, it didn’t.
Aggregation
What is Risk Aggregation? Aggregation is an insurance mechanism where an insurer minimises exposure to numeros claims related all to the same risk by looking at shared assets/facts between the different policyholders on their book.
As an example, think about Hosting providers, when parts of AWS go down (as they have multiple times in the last 30 days) all companies that use that AWS region potentially have some type of business interruption due to that incident that could potentially be covered by their policy. So as an insurance provider, you want to make sure your book has a healthy distribution across other providers like GCP or Azure.
Combining the two…
So how does log4j and aggregation come together?
If you read any article about Log4J you will see titles such as “CYBER PANDEMIC - Log4J Catastrophe”, the reason for this is because of the potential attack surface for Log4J.
Let’s take a look at the vendors and products that use Log4J (we can do this by pulling the updated data from the NCSC github repository and plotting a force graph that shows the connections for those vendors and products).
Looking at the data from this perspective it shows how widely used Log4J really is, and if all you’re using is this measure it’s easy to see why the industry as a whole had a mild panic attack.
However we have data that can help us understand the situation better and give a better perspective than “the end of times are coming for cyber” as many vendors did, including to some of our partners with whom I spent time on the phone over the last few weeks, because you see, the devil is in the details….
I’ve seen multiple presentations about aggregation and a lot of them use force graphs to represent aggregations, hell, I’ve done it myself in my post on COVID supply chain cyber analysis.
“Why does how you visualize it matter Tiago?”, I hear you ask. It matters because visualizing it as a force graph gives you an idea of the relationship/dependency which is what part of what aggregation is about BUT it doesn’t paint a realistic picture of how the world works, as it shows all assets as homogeneous and they are not, as we will see in the next sections.
Come on in sankeys!
It’s widely known that Microsoft Windows suffers from ransomware a lot more than other operating systems like Linux or OSX. So does that mean that Windows should be taken as a whole when thinking about aggregation scenarios for ransomware? Absolutely not. There are two reasons which make it extremely important to look one or two levels deeper if we’re trying to get an accurate calculation of potential aggregation scenarios
Reason 1: Assets ain’t all the same!
For the lat 7 years my job has been scanning the entire IPv4 space and parts of V6 to understand what gets exposed to the internet. To look at Windows versions, I grabbed our worldwide scans for SMB as our module for scanning SMB has Operating system identification.
On our SMB scans where we were able to extract the OS version, we found a total of 1,184,706 machines on the internet.
Now if we only think about the attack surface a vulnerability has based on the high level target (aka only “Windows”), this is a HUGE number. However lets take a look at a vulnerability announcement details, lets pick Bluekeep, which is a vulnerability widely known to have been really bad for Windows.
 Source: CISA
Source: CISA
We can see that not all versions of Windows are vulnerable. CISA details which versions are vulnerable, and now we know only a subset of Windows is vulnerable to bluekeep. Now lets take a look at our world scans with the break down of Windows versions
Using today’s numbers, our of 1,184,706 only 318,251 are vulnerable. Still a scary number. Notice the shift in change from a force graph to a sankey diagram in the display forces you to think a level deeper about the targets for this vulnerability. We can drill even deeper,by scanning for machines vulnerable to Bluekeep, as we have a module for it.
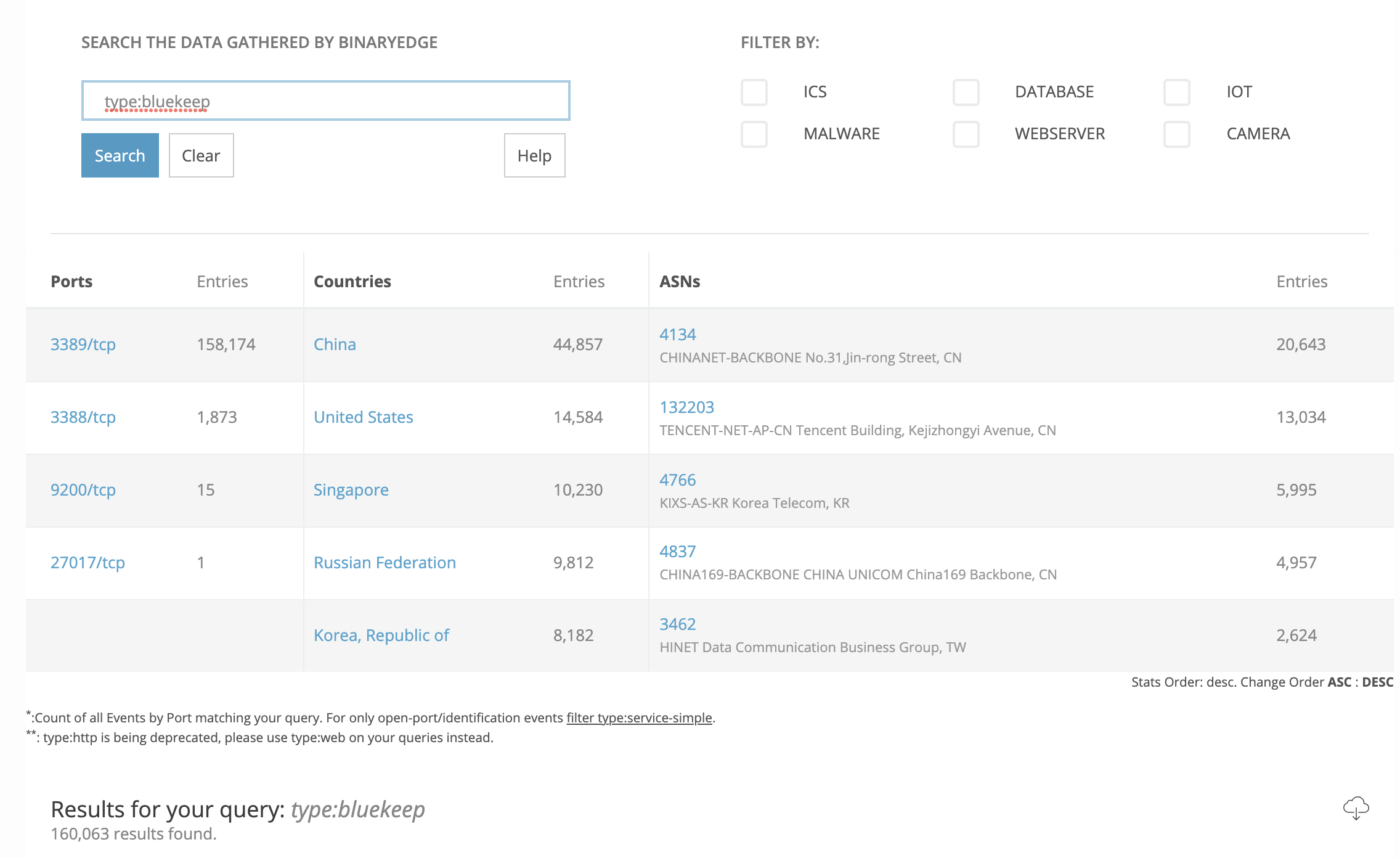
We end up with 160,063 machines vulnerable. Still a big number but so much smaller than our initial 1,184,706. So even though we had a vulnerability for Windows, not all Windows were vunerable, and we can go through this same exercise with any other vulnerability.
Reason 2: Assets aren’t all located in the same homogeneous environments either nor to they have homogeneous behaviours
Back to Log4J, looking at our vendor usage graph, if its so widely used, why have we not seen an absolute meltdown of the internet and the biggest botnet ever being built ?
This is because the attackers still need to figure out how to reach log4j, and how to customize the attack to fit the environments of the targets that are potentially attackable.
We observed on the first few days, a lot of internet spraying / scanning using the “user-agent” string.
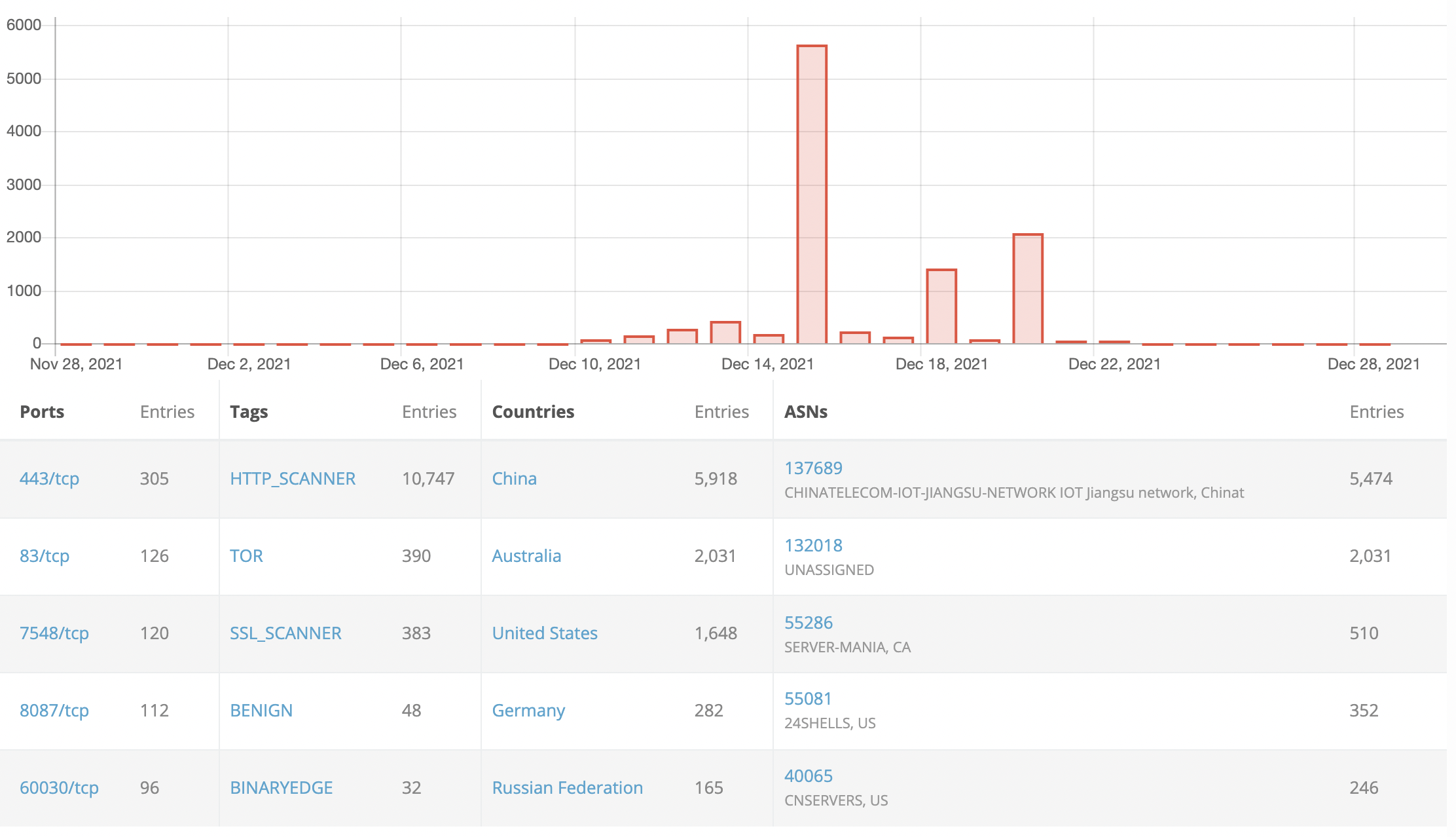
This is the low hanging fruit version of this attack. The easiest way for attackers to reach log4j was injection the vulnerability into user-agent header and then whatever logged that header and was vulnerable would be exploited. We did the same type of scanning and the number of machines vulnerable that we discovered was close to 40.000 IP addresses that we received some type of callback across port 80, 443 and 8080 and these have been decreasing day over day.
So what about the rest of all the applications that are vulnerable? Those require that attackers start thinking about customization of the payloads, techniques and tactics they are using, which when compared to the ROI of exploiting other vulnerabilities at mass scale, just make it that it isn’t worth it.
An example of trying to exploit VMWare Vcenter has been posted and quoting GossitheDog “Exploiting vendor specific products isn’t easy”.
On top of all the customization per applications, attackers will have to deal with WAFs, XDRs and other types of defenses that start building over time, so right now, if you’re a defender, act. You have an advantage.
Are you saying we won’t see Log4J exploitation?
No. I’m saying we won’t see some mass exploitation of internet exposed Log4J or a worm that will lead to massive amount of Ransomware, this vulnerability is a very powerful tool that has just been added to attacker belts to use for lateral movement and you will see a realllly long tail of this being used internally. It’s important not to dismiss it and to keep up on matching or removing the exposure.
Conclusion
For all security vendors and insurance modelling vendors that I saw over the last few weeks 🚑 chasing this vulnerability and selling that your product could defend or help with a “cybercatastrophe” I suggest that you take a good look in the mirror and review how you’re behaving in this industry as that type of behaviour is not helpful in any way even if it might boost a couple of sales of your product.
Use data, understand how a vulnerability works, setup sensors and observe the behaviour of attackers and what the exposure looks like a bit more indepth than just pulling BinaryEdge, Shodan, Censys data for the product version. Cyber is a type of risk that is much more dynamic and complex than most and can’t be treated with same typical aggregation techniques that have been used in the past, just like how underwriting needs to be treated differently.